What is Keda?
Today we explore and demonstrate using Kubernetes Event-driven Autoscaling KEDA to autoscale workloads (e.g. applications) within a Kubernetes cluster.
With KEDA we’ll be able to easily trigger the automatic scaling of a workload (up or down) using events/data from various vendors, databases, messaging, systems, CI/CD and more. Examples include; RabbitMQ, Postgresql, MongoDB, AWS SQS Queue, Azure Storage Queue, etc but for this blog, I’ve decided to go with Prometheus and Redis due to the simplicity for setting up the demos.
I have included a full list of event sources.
HPA and KEDA
Kubernetes does offer a built-in solution for autoscaling in the form of the Horizontal Pod Autoscaler (HPA). However, it lacks certain features and has several limitations. KEDA extends the functionality of the HPA; enhancing it with additional functionality and resolving the HPA limitations. As you use KEDA you may notice a HPA object in your Kubernetes cluster, created by KEDA.
Behind a KEDA installation is KEDA fetching data from an event source and sending the data to Kubernetes and the HPA. Once HPA has the data from KEDA it’ll autoscale the target workload.
- You may read about these details in this CNCF Blog by members of the Alibaba Cloud team.
- You can read more around HPA.
KEDA Use Cases: External/Custom Metrics & Scaling Jobs
The typical use case for autoscaling would be to scale up if an application has received a sudden spike in web traffic and to scale down when the amount of web traffic is low enough to save costs and resources. CPU and memory metrics are the typical indicators used to determine traffic levels.
However, there are cases where something else, other than the amount of web traffic, is affecting the performance of an application. In which case, you’ll want to use external or custom metrics (e.g. from Prometheus).
An example is an application in charge of processing items in a list or queue, where the performance would be based on how quickly each item can be processed and how quickly the list/queue can be emptied. Unfortunately, CPU and memory metrics aren’t the best indicators that’ll help you prevent a list/queue from getting too large. Instead, KEDA can be used to create (i.e. scale up) a new Kubernetes Job each time a new item is added to the list/queue (i.e. an event is triggered).
KEDA CRDs: ScaledObjects vs ScaledJobs
KEDA comes with two CRDs called ScaledObjects and ScaledJobs.
- The ScaledObject is used for scaling a Kubernetes
Deployment,StatefulSetor custom resource. - The ScaledJob is used to run and scale Kubernetes
Jobs.
Note: The Underlying HPA Object
One noticeable difference between the two is that deploying a ScaledObject will also result in an HPA object being created to handle the autoscaling of the workload. However, deploying a ScaledJob object will NOT result in an HPA object being created, instead it has the Jobs specification defined inside it that is used to create a new Kubernetes Job each time the defined event is triggered.
Note: HPA’s Custom and External Metrics Limitation
The HPA does support using external and custom metrics for autoscaling, so you don’t necessarily have to use KEDA if you want external and custom metrics. However, a few requirements must be met to enable the HPA to do so. These requirements include:
- enabling the API aggregation layer
- registering the
custom.metrics.k8s.ioandexternal.metrics.k8s.ioAPIs - Unsetting
--horizontal-pod-autoscaler-use-rest-clientsor setting it totrue
You’ll typically want your cluster administrator(s) to set up the support metrics API’s. We also wrote a blog about how you can use the HPA with Prometheus. I’d recommend reading it and comparing it how it can be done with KEDA.
A problem you’ll find with this approach is despite being able to choose from a variety of metric adapters to fetch external and custom metrics from only one metric server can be run inside a cluster meaning you’ll only be able to use one metric adapter.
Fortunately, this is one of the limitations solved by KEDA.
Note: Scaling Custom Resources
If using the ScaledObject to autoscale a custom resource, the object’s Custom Resource Definition (CRD) must define the /scale subresource otherwise KEDA will not be able to scale the custom resource. You can confirm if the CRD defines the /scale subresource by running kubectl get crd CRD_NAME -o yaml > CRD_SPEC.yaml and checking if .spec.versions[X].subresources.scale exists:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
spec:
versions
- name: v1
subresources:
scale:
An example where you might choose to scale a custom resource is if you’re using a service that is using the Kubernetes Operator Pattern. This pattern often involves monitoring a custom resource that declares how many replicas the Operator should create and manage. The flow is usually as follows:
- Deploy the Operator (e.g. in the form of a
Deployment). - Deploy the custom resource object with the number of replicas declared.
- The Operator detects the custom resource and examines its contents.
- The Operator creates the workloads based on the specification declared in the custom resource object, including the number of replicas.
In this situation, if you just autoscaled the workload (a Deployment or Statefulset) created by the Operator, the Operator would just scale the workload back to the number of replicas still declared in the monitoring custom resource. There’ll probably be a back and forth with the underlying HPA attempting to scale the Deployment up and the Operator scaling it back down. This is why you want the number of replicas in the custom resource to be autoscaled.
However, as noted above the CRD of the custom resource monitored by the operator must define the /scale subresource.
You can find more information:
- around the
/scalesubresource. - about the Operator Pattern.
Note: Scaling to or from Zero
This is mainly for ScaledObjects. If you want to set the starting or minimum replica count to 0, you need to enable the HPAScaleToZero feature gate. If this feature gate is not enabled and you set the minimum replica count in the ScaledObject to 0, KEDA will create an HPA object with a minimum replica of 1.
Note, at the time of writing, the HPAScaleToZero has been in alpha since Kubernetes version 1.16.
A possible alternative to enabling the HPAScaleToZero feature gate is to use a ScaledJob which starts from 0 (i.e. no Jobs) and always resets back to 0 once all Kubernetes Jobs are finished.
I have provided a link so you can learn how to enable feature gates
KEDA Demos
We will demonstrate the following three things.
- A Kubernetes
Deploymentbeing autoscaled based on Prometheus metrics. - A Kubernetes
Deploymentbeing autoscaled after a Redis list reaches a certain length. - A Kubernetes
Jobbeing created when an item is added to a Redis list.
The first two will involve using KEDA’s ScaledObject and the last one will using KEDA’s ScaledJob.
Before going into the actual demos, I’d like to provide some details about how they were setup so that you can reproduce them locally and follow the basic flow each one will go through.
First, I have installed KEDA using the official helm chart onto a namespace called keda-demo within the Kubernetes cluster. You can find the KEDA installation instructions in the official documentation. At the time of writing, version 2.3 was used.
Second, each demo will go through the following general flow:
- The event sources and target workloads will be deployed.
- A KEDA CRD object is deployed which contains the autoscaling configurations, including which events will trigger the target to be autoscaled.
- The event will be manually triggered.
- The autoscaling of the target workload will be observed.
*Resources used in these demos are found and documented in this GitHub repository.
KEDA Demo #1 - KEDA ScaledObjects: Autoscaling with Prometheus Metrics
This demo will showcase a basic example of how someone can setup an application to be autoscaled based on metrics collected by Prometheus.
Prerequisites
For this demo to work, you’ll need:
- a Prometheus server
- an application that can export metrics that can be scraped by Prometheus.
- an application that’ll be the target for autoscaling.
I’d recommend the following:
- Install the Prometheus Operator into your Kubernetes cluster and have it configured to look for
ServiceMonitors in thekeda-demonamespace. You can use the community helm chart to install it. - For the application that exports Prometheus metrics, I’ve chosen to use the open-source PodInfo application. I installed it into the
keda-demonamespace using the helm chart. I’ve made sure to deploy it with theServiceMonitorenabled withhelm install podinfo --namespace keda-demo podinfo/podinfo --version 5.2.1 --set serviceMonitor.enabled=true --set serviceMonitor.interval=15s - Any
Deploymentobject with 1 replica.
Showcase
With the above setup, I can produce the demo below:
In the demo, I created a ScaledObject object that:
Has a target workload to autoscale (prom-scaledobject.yaml)
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: target-workload
Has a Prometheus server to monitor with a PromQL query and a threshold value that’ll determine what the value of the query has to be before the target workload is scaled up. More details about the Prometheus trigger.
# prom-scaledobject.yaml
spec:
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-host>:9090
metricName: promhttp_metric_handler_200_requests_total
query: increase(promhttp_metric_handler_requests_total{namespace="keda-demo", code="200"}[30s])
threshold: '3'
Configured the underlying HPA object to allow only one pod to be created or deleted within a 3 second period.
# prom-scaledobject.yaml
spec:
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 30
policies:
- type: Pods
value: 1
periodSeconds: 3
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Pods
value: 1
periodSeconds: 3
You can find the manifest file used in the demo.
With the scaling infrastructure for the target workload setup and deployed. I repeatedly ran the curl command against the PodInfo service to increase the value outputted by the Prometheus query, thus triggering the target workload to be scaled up.
If the value outputted by the Prometheus query dropped below the threshold, the target workload would eventually be scaled back down.
Note, since I deployed PodInfo with no ingress I used telepresence to connect my local workstation to the Kubernetes cluster allowing me to curl the PodInfo service at <SERVICE_NAME>.<NAMESPACE>:<PORT_NUMBER>. If you don’t want to use telepresence, the alternative is to exec into a pod that can curl the PodInfo service or to deploy an ingress for the application.
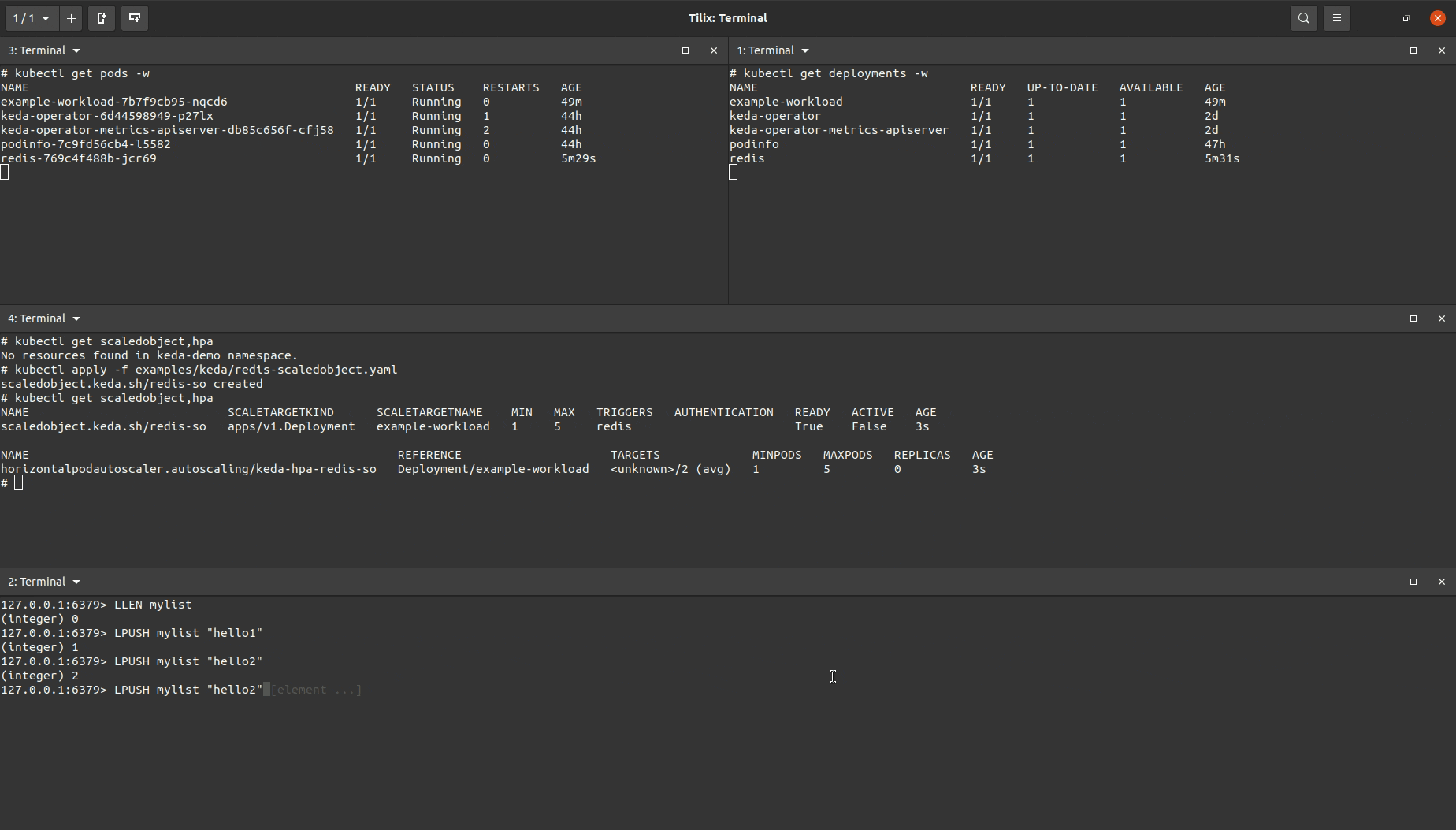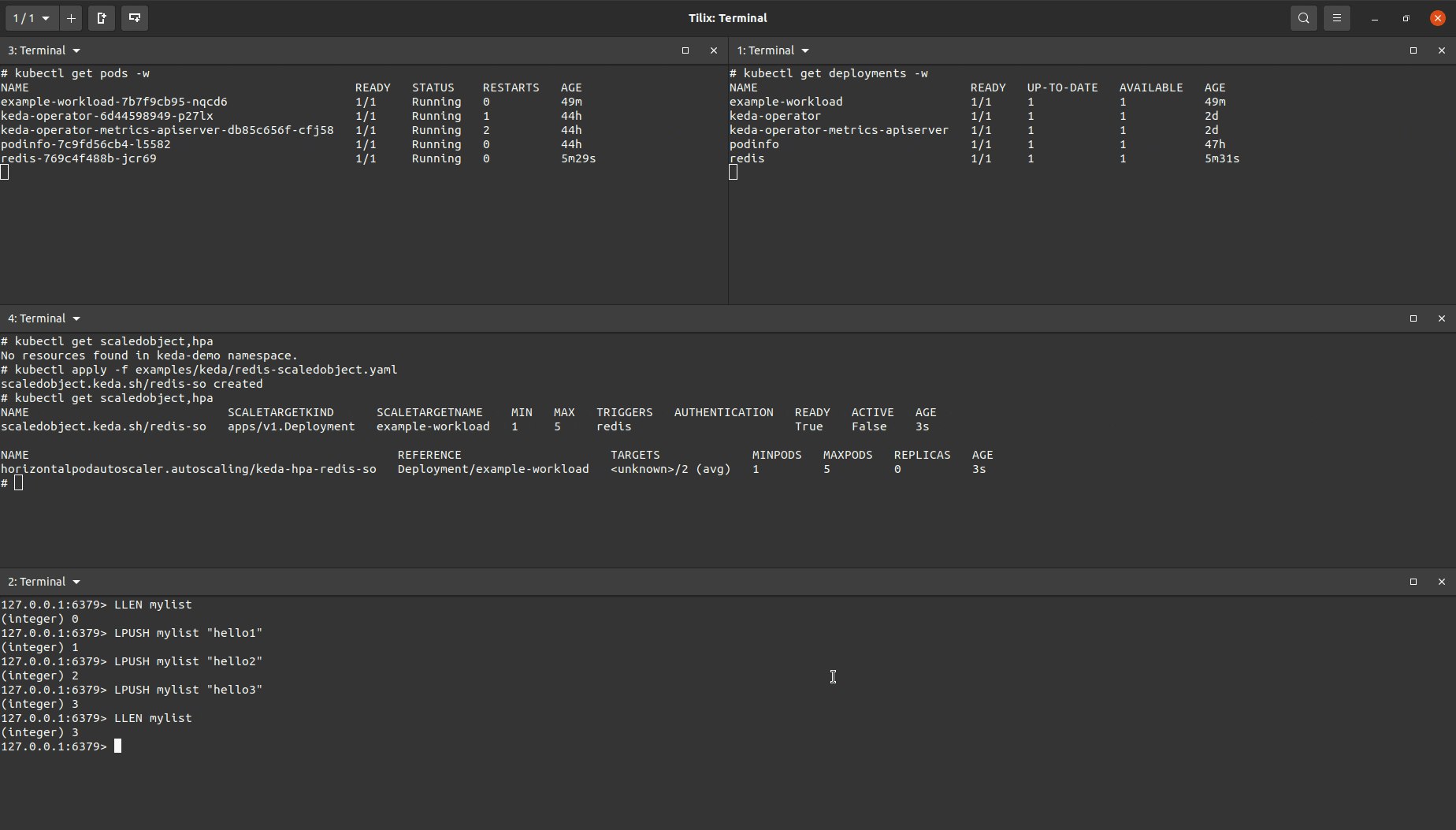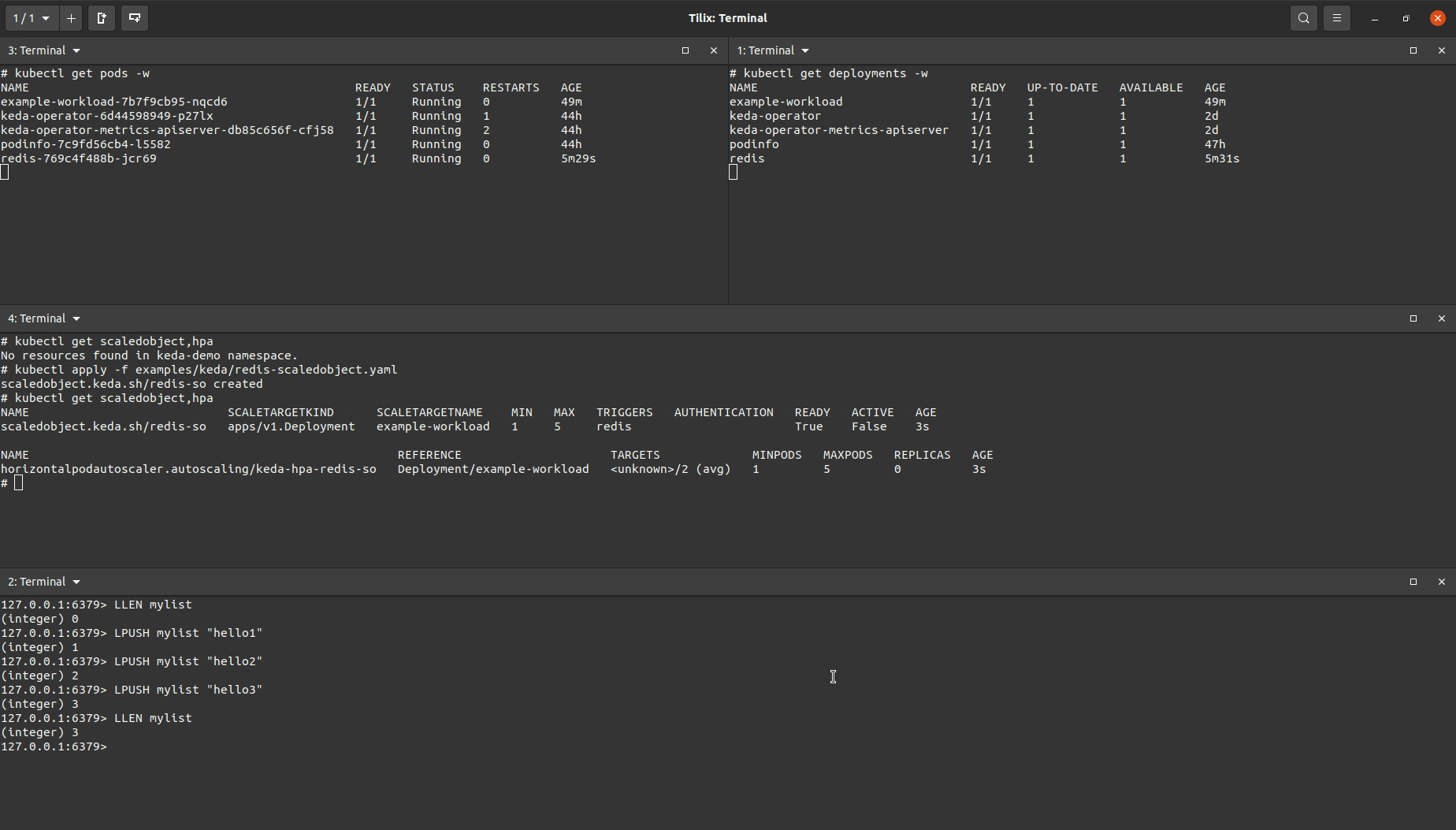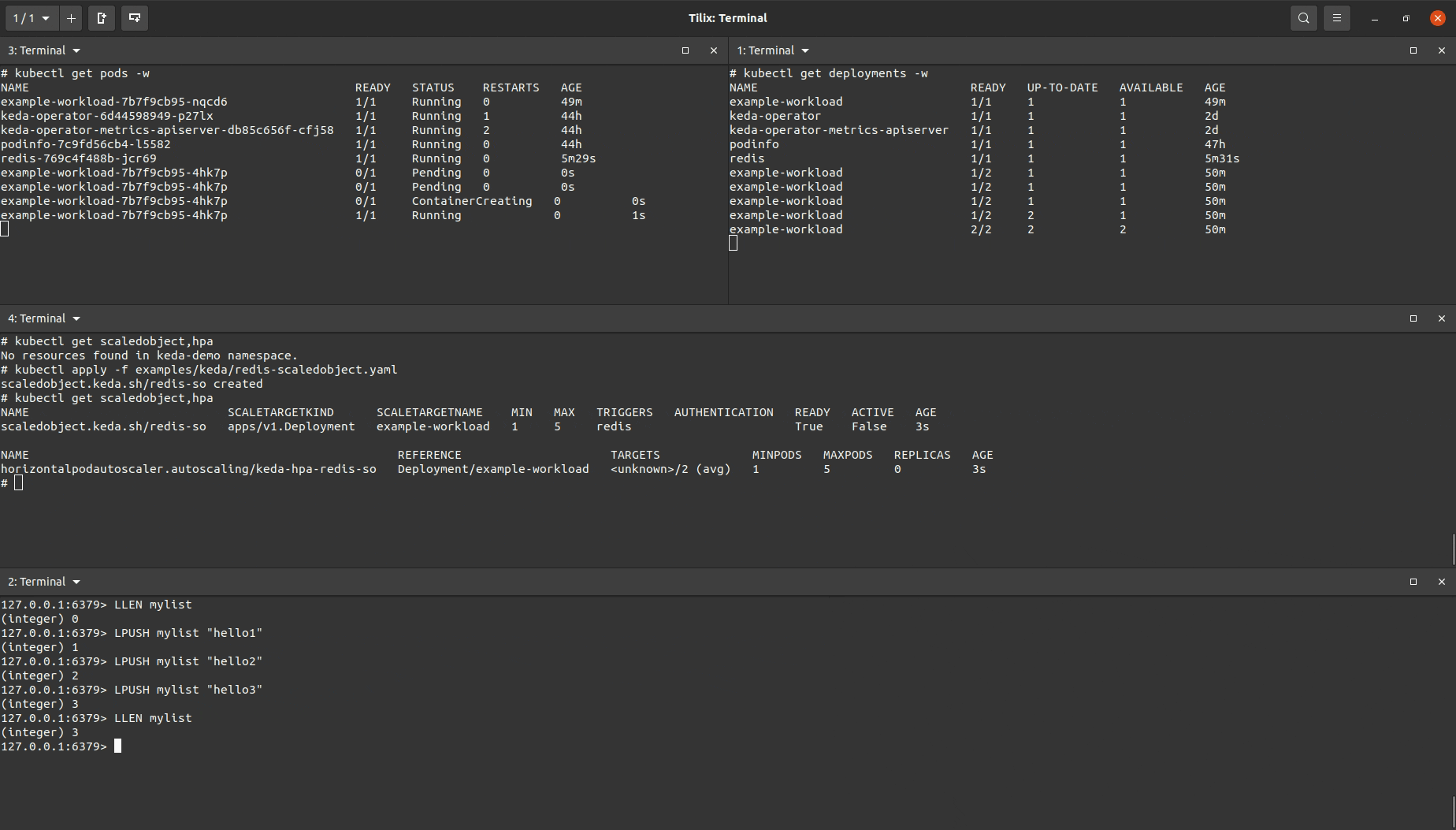
KEDA Demo #2 - KEDA ScaledObjects: Autoscaling with a Redis List
This demo will showcase a basic example of how someone can setup an application to be autoscaled based on the length of a Redis list.
Prerequisites
For this demo to work, you’ll need to deploy:
- A Kubernetes
DeploymentorPodobject with a redis container. - A Kubernetes
Servicethat is configured as a load balancer for the above redis container. - Any
Deploymentobject with 1 replica.
Showcase
With the above setup, I can produce the demo below:
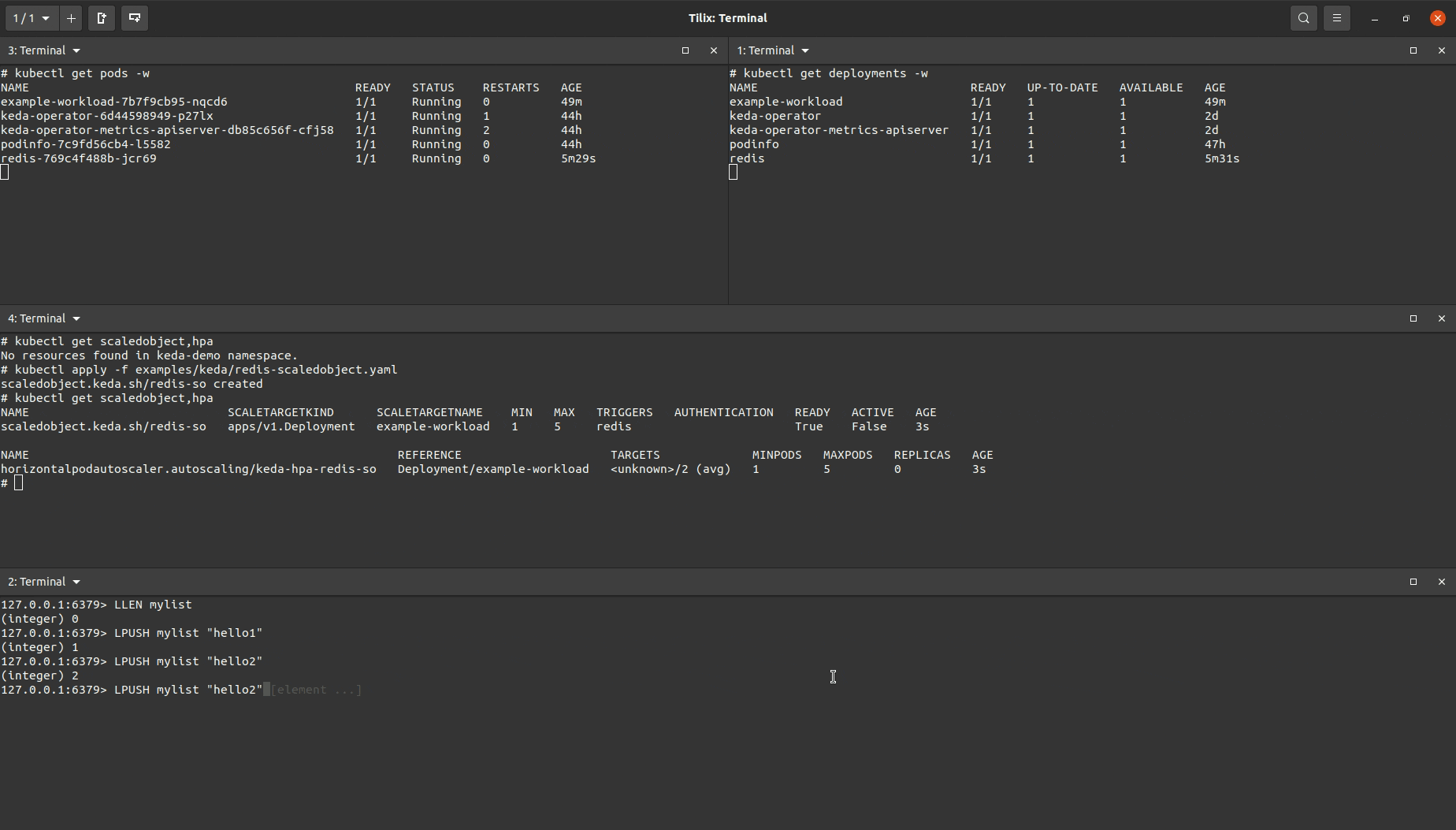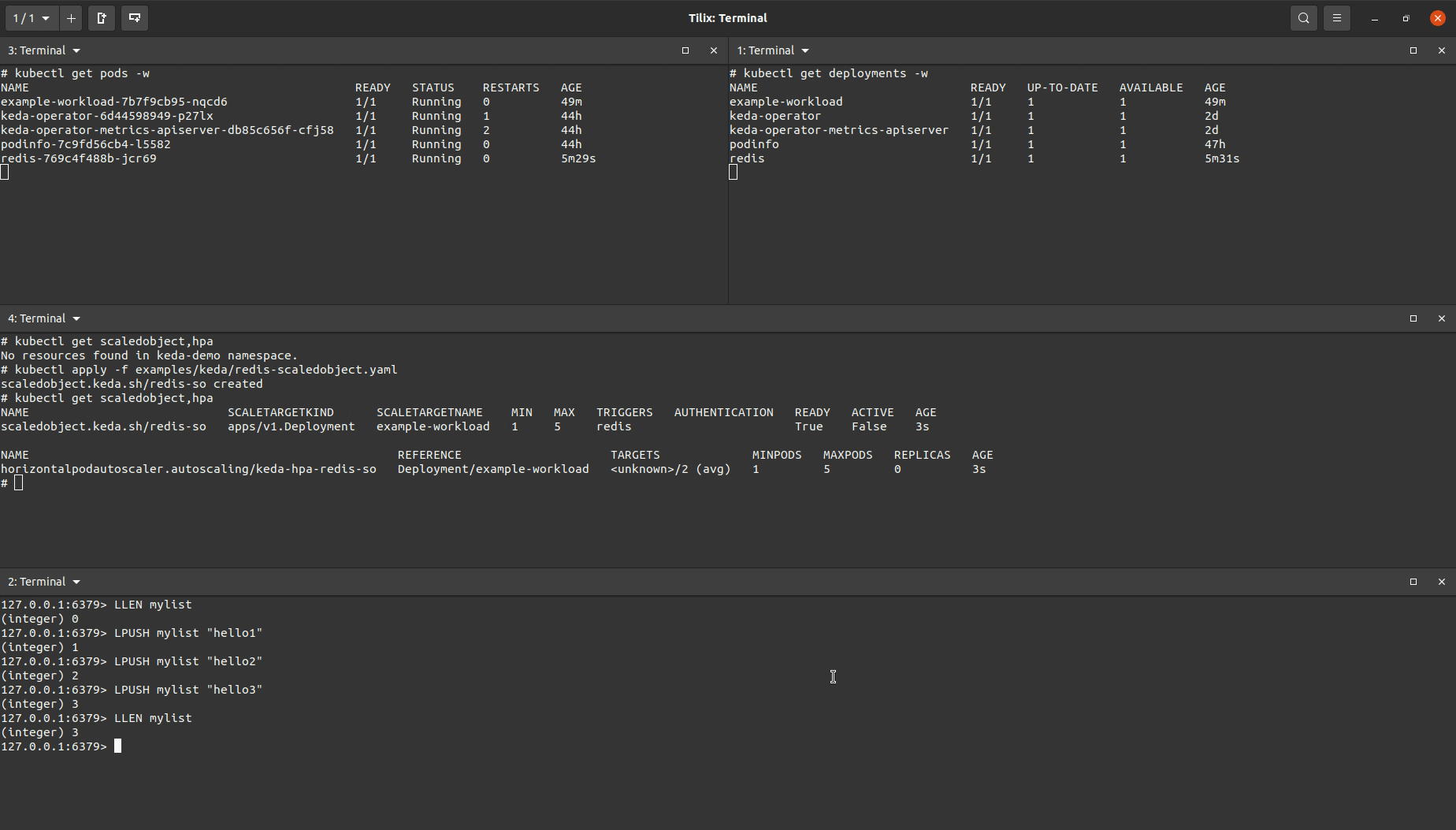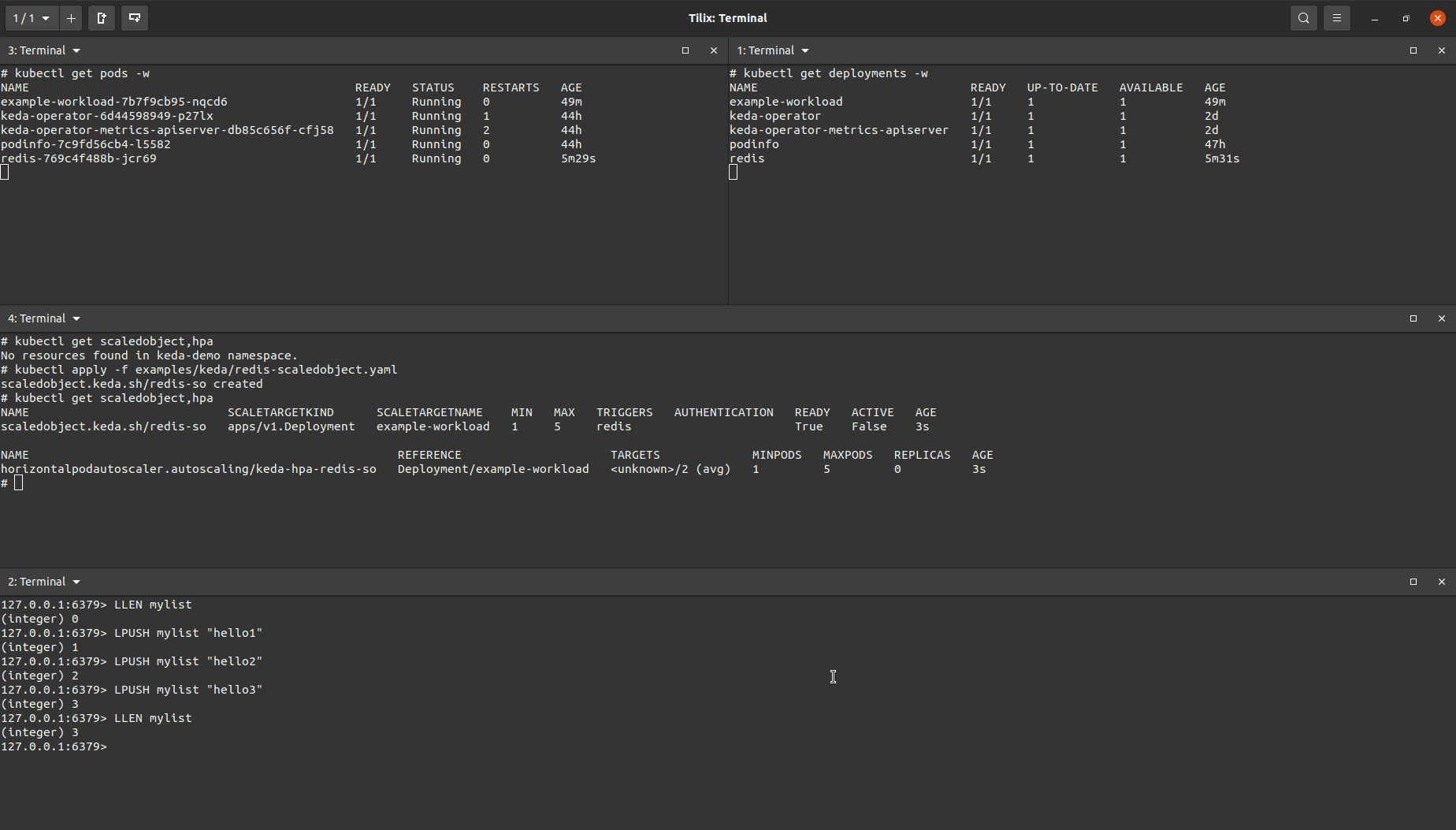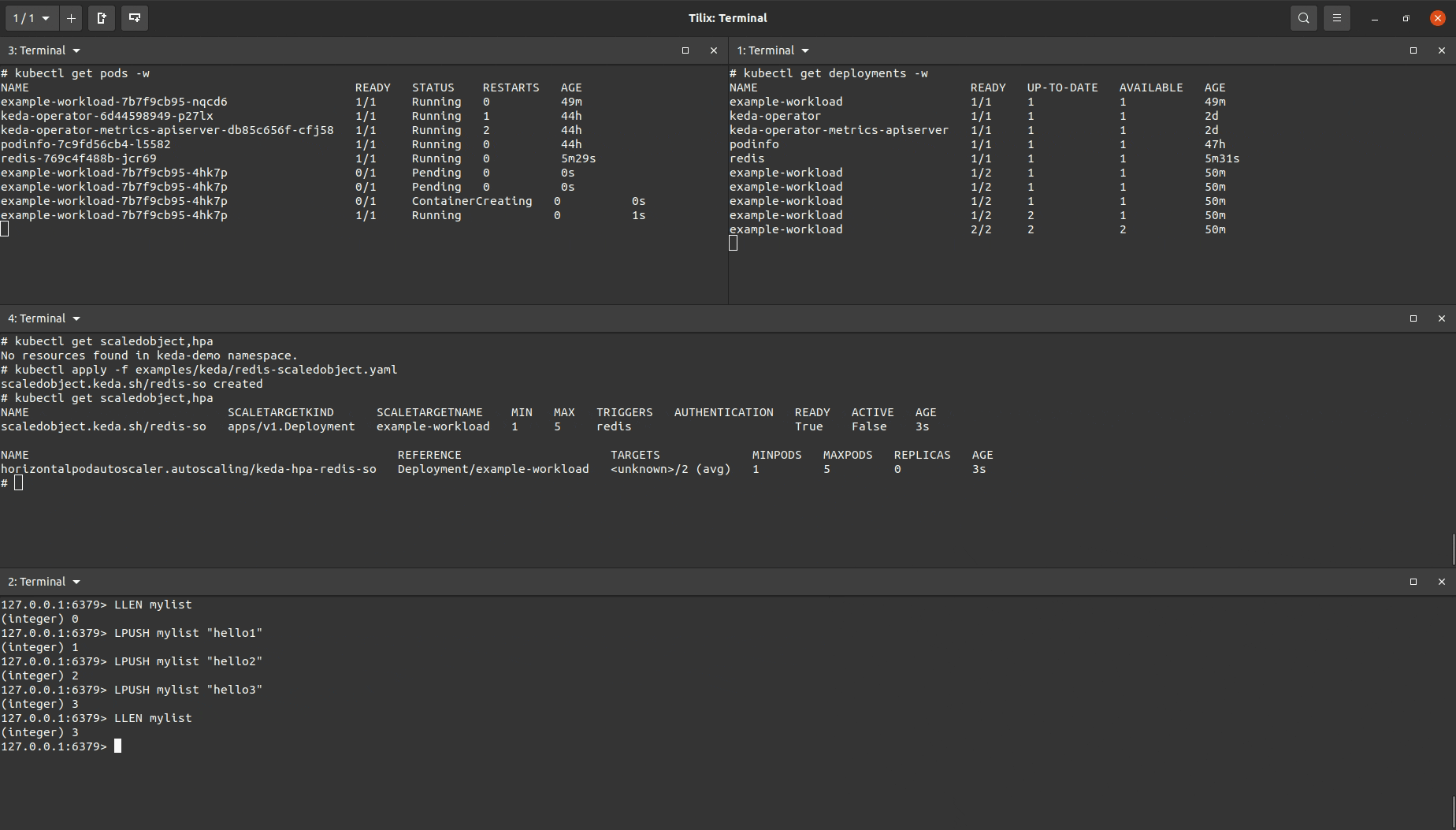
I created a ScaledObject object that was almost identical to the one used for the Prometheus demo above but with a different trigger (note, it is possible to include multiple triggers in the same ScaledObject manifest).
# redis-scaledobject.yaml
triggers:
- type: redis
metadata:
address: redis.keda-demo.svc.cluster.local:6379
listName: mylist
listLength: "3"
You can find the manifest file used in the demo.
You’ll see the target workload being scaled up after I added enough items to the Redis list to increase the length of the length so that it was greater than the value set to listLength. After removing items in the list to drop the list length below the set listlength the target workload will eventually be scaled down.
KEDA Demo #3 - KEDA ScaledJobs: Autoscaling Jobs with a Redis List
This demo will showcase a basic example of how someone can setup a job to be autoscaled based when a Redis list is being populated.
Prerequisites
In order for this demo to work, you’ll need to deploy:
- A Kubernetes
DeploymentorPodobject with a redis container. - A Kubernetes
Servicethat is configured as a load balancer for the above redis container.
Showcase
With the above setup, I can produce the demo below:
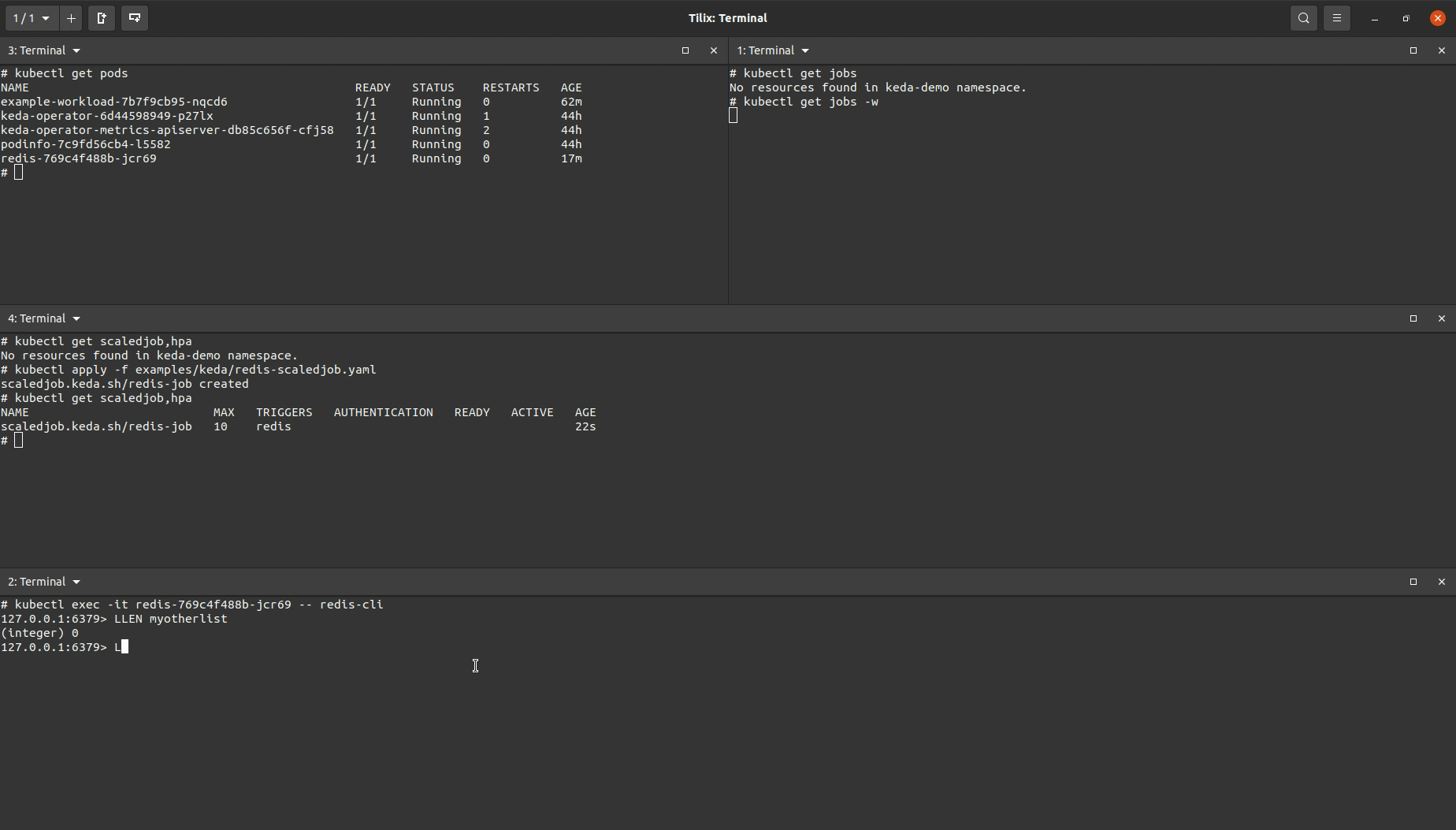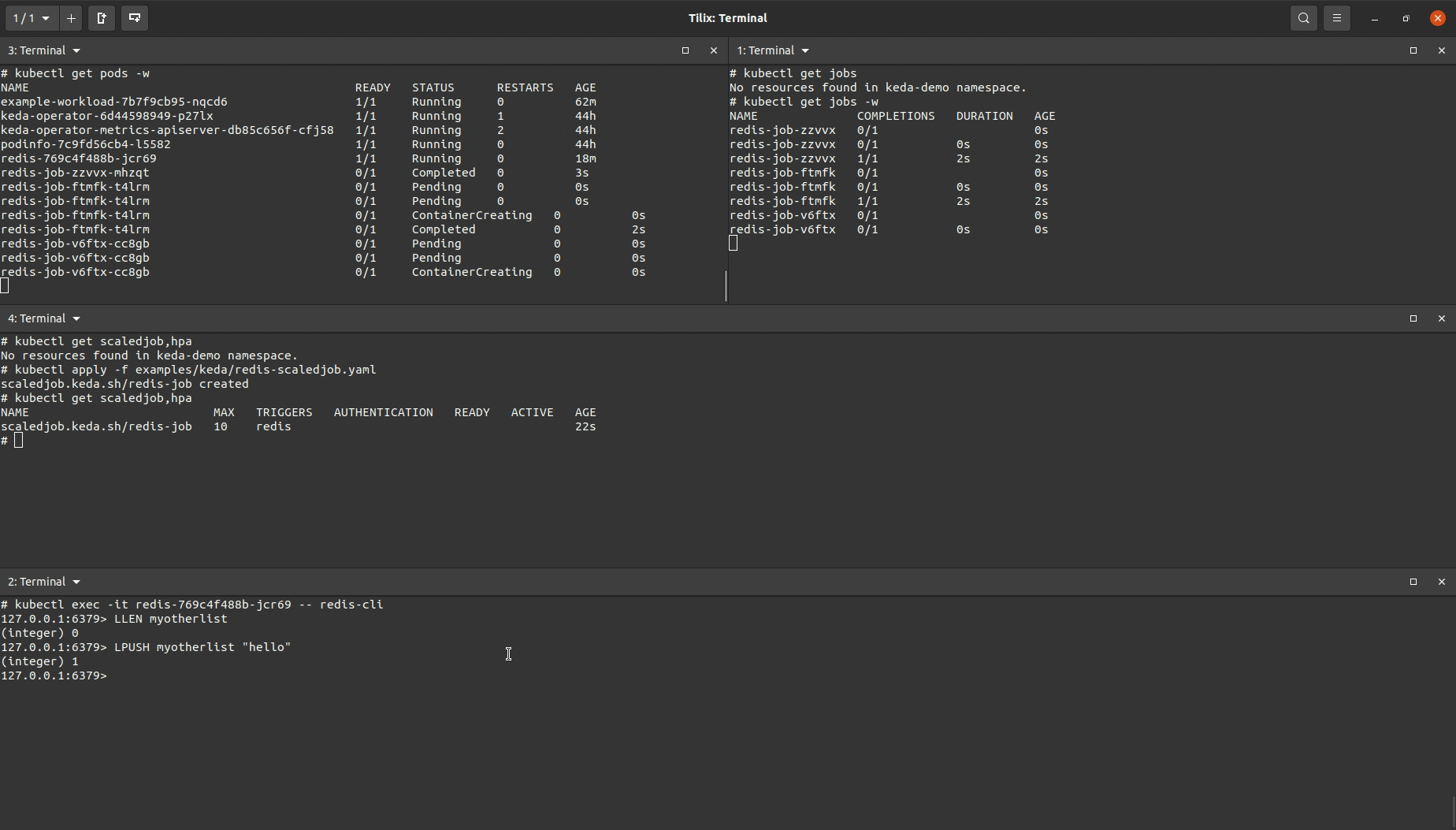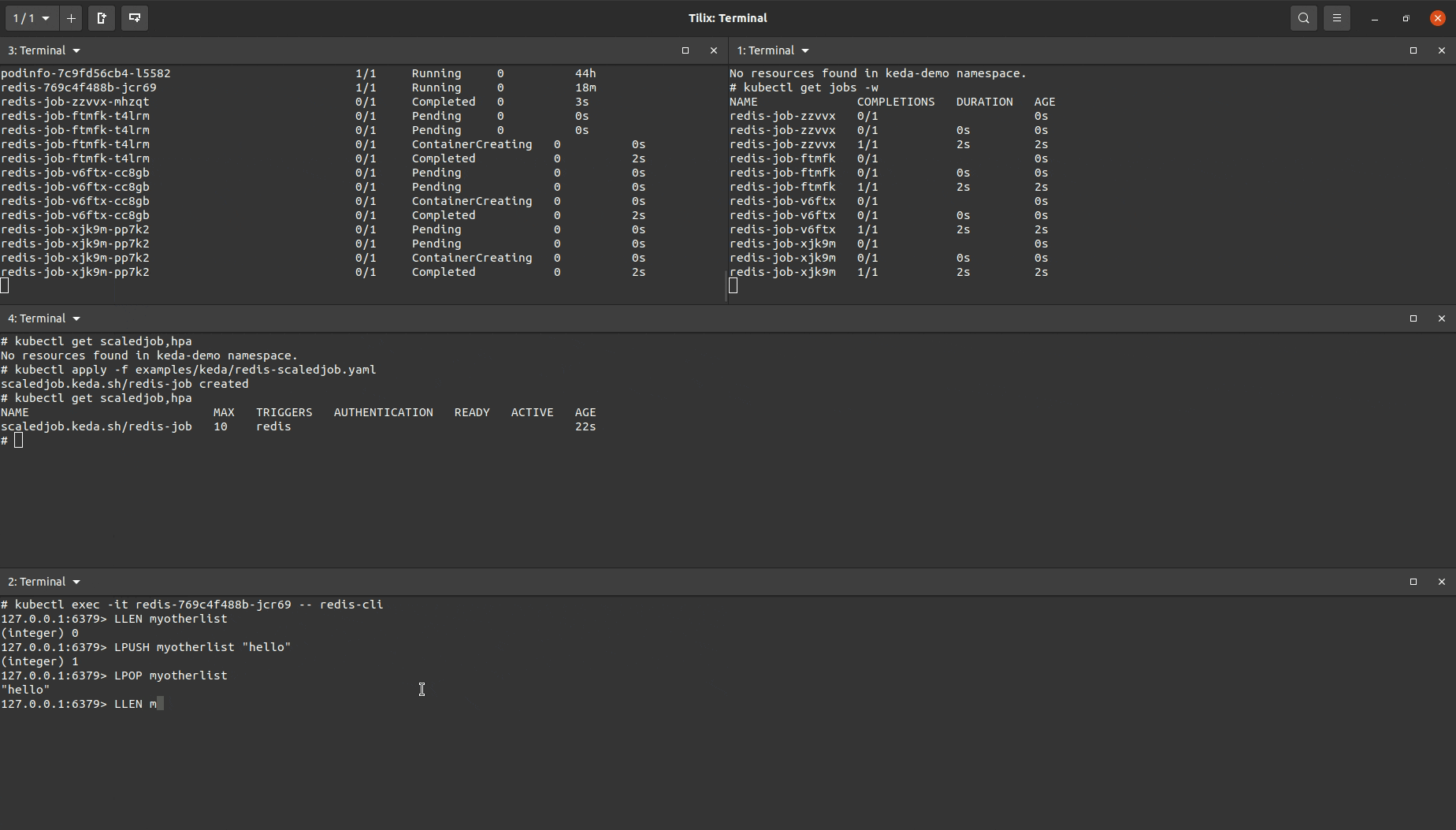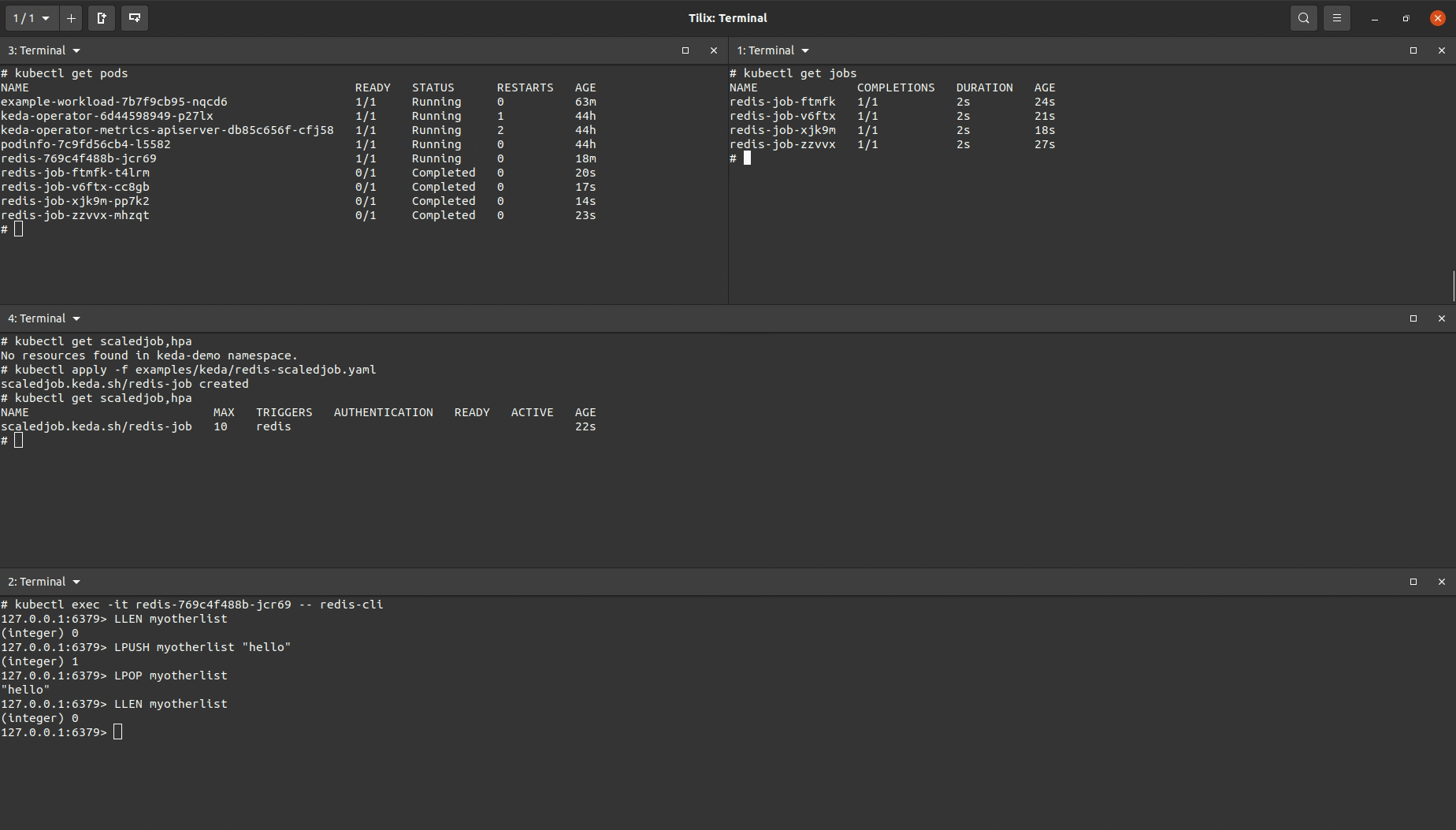
This is the trigger being used for the ScaledJob:
triggers:
- type: redis
metadata:
address: redis.keda-demo.svc.cluster.local:6379
listName: myotherlist
listLength: "1"
As shown in the demo, multiple Kubernetes Jobs are being repeatedly created when an item is added to the list. Once the item is removed, no more Jobs created. In practice, each job would be consuming this item, removing it from the list and creating the effect of one Job handling one item. Two example use cases are messaging queues and running long running executions in parallel as items/data come in.
The specifications for all jobs being created are declared within the ScaledJob object.
spec:
jobTargetRef:
parallelism: 1
completions: 1
activeDeadlineSeconds: 30
backoffLimit: 6
template:
spec:
containers:
- image: alpine:3.13.5
name: alpine
command: ['echo', 'hello world']
restartPolicy: Never
You can find the manifest file used in the demo.
DevOps Engineer Final Thoughts on KEDA
That’s all for this blog on KEDA. The KEDA website says it is “Application autoscaling made simple” and I agree with it. With the event sources already in place the only thing I had to do to enable autoscaling is to deploy KEDA and then a single KEDA custom resource object.
I’m looking to forward to using KEDA in the future and integrating it’s autoscaling functionality with our internal services.
You can reach out to us and book a meeting with a Cloud Platform Engineer if you want to learn more.