High Availability Requirement
You’ve finally containerised your cloud native web application, and its components are redundant and scalable. You’ve constructed your ReplicationControllers and Services. The only remaining single point of failure remaining is your cluster master itself! In this post, we’re going to look at setting up a high availability Kubernetes master.
Master Node Building Blocks
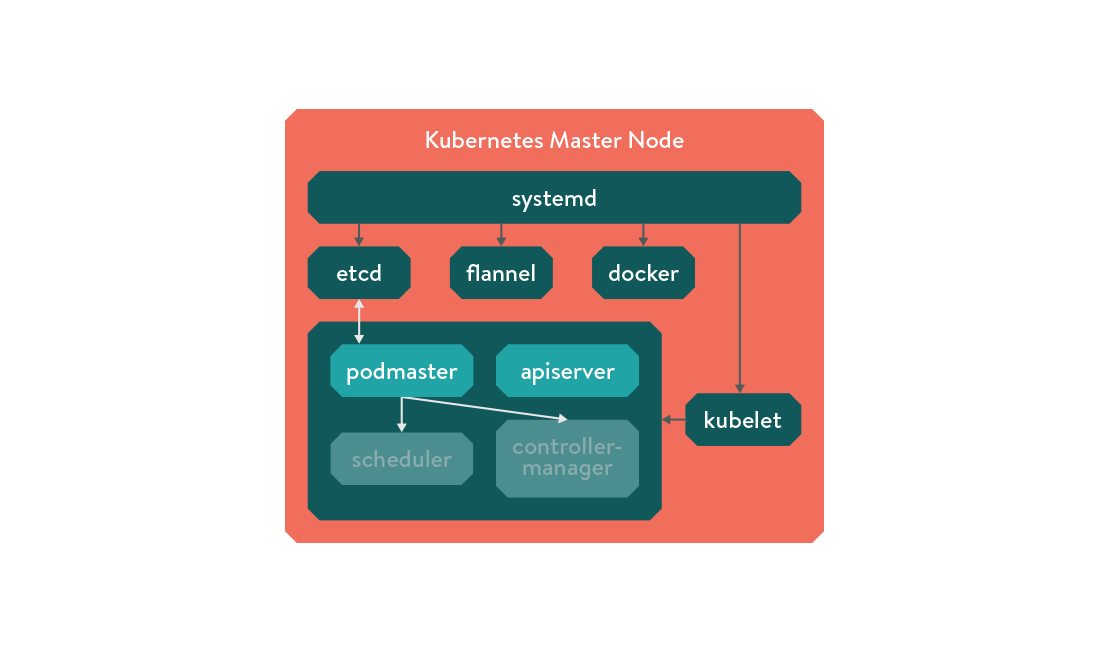
The first step to building a reliable master node is to start with a monitoring system that restarts failed processes on a single host. Seeing as we use CoreOS, we use SystemD, although the official HA documentation uses monit. Either way, set up your process monitor to start the fundamental building blocks:
etcd- holds the cluster state- container runtime - Docker in this case, but rkt support is looming on the horizon
- container networking fabric - this can be cloud provider specific, but we use Flannel for now
- Kubelet process
Why use kubelet as another process manager when we’re already using systemd? As Kubelet manifests are the same files that you could otherwise pass directly to a running cluster, you can add resource limits and update the binaries by updating their containers without rebuilding your unit files. It’s also convenient to just drop in any cluster-ready services you may have already constructed elsewhere.
In order to provide a high availability data store, we will need to set up some clustered etcd instances. You can do
this manually, or by using a discovery service - both methods are well documented. It’s also recommended you keep your
etcd storage directory on a distributed filesystem, for example Gluster, Ceph or a cloud provider’s block device.
Configuration and Kubelet Manifests
You now need to configure your master node appropriately. If you’re doing this as an experiment, you can simply copy the configuration from an existing cluster. The appropriate files are:
basic_auth.csv- basic auth user and passwordca.crt- Certificate Authority certknown_tokens.csv - tokens that entities (e.g. the kubelet) can use to talk to the apiserverkubecfg.crt- Client certificate, public keykubecfg.key- Client certificate, private keyserver.cert- Server certificate, public keyserver.key- Server certificate, private key
The Kubelet process scans a specified directory for Kubernetes manifests, and executes them. To start with, we want to
run a copy of the APIserver on each node (it’s stateless, so running it on each node permanently is fine.) Edit the
manifest to your liking, then add it and the check that the Kubelet has started it using docker ps.
If everything has started correctly, you have created a stateless master node which you can scale horizontally by spinning up identical copies. You should run them behind a load balancer of your choosing, which is again cloud provider specific. Once this is done, when configuring your worker nodes, set their APIserver configuration to point to the load balancer and they should carry on working as usual! Note that your certificates may have to be regenerated to contain the IP address of your load balancer rather than the master nodes themselves!
Podmaster and Leader Election
While the Kubernetes APIServer is stateless, the Scheduler and Controller-manager are not. Now we are running multiple masters we will need to have an implementation of leader election. Enter podmaster!
Podmaster is a small utility written in go that uses etcd’s atomic “CompareAndSwap” functionality to implement master
election. The first master to reach the etcd cluster wins the race and becomes the master node, marking itself as with
an expring key that it periodically extends. If it finds the key has expired, it attempts to take over using an atomic
request. If it is the current master, it copies the scheduler and controller-manager manifests into the kubelet
directory, and if it isn’t it removes them. As all it does is copy files, it could be used for anything that requires
leader election, not just Kubernetes!
Final Kubernetes Architecture
The overall cluster architecture looks something like this:
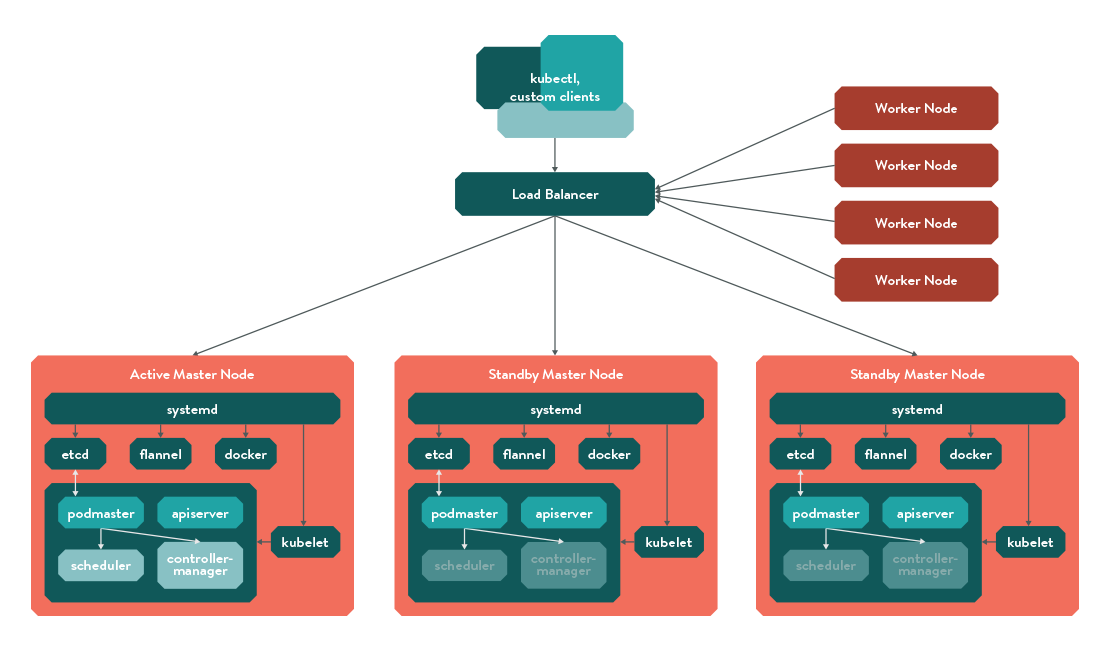
In time, high availability is supposed to be baked in to Kubernetes, but for now, the podmaster (of the universe) is considered best practice!